

The terms ‘data sovereignty’, ‘data residency’ and ‘data localization’ are often a source of confusion for businesses managing data across borders, especially on cloud infrastructure. They are in fact used so interchangeably that their individual meaning has become lost.
This interchangeable use is evidenced most clearly by the remarkable consistency in the number of searches each term receives in search engines like Google. Despite various peaks brought about by new legislation and news articles, global interest in ‘data residency’ and ‘data localization’ follow almost exactly the same patterns, with ‘data sovereignty’ receiving slightly less search volume but still following the same rough trend.
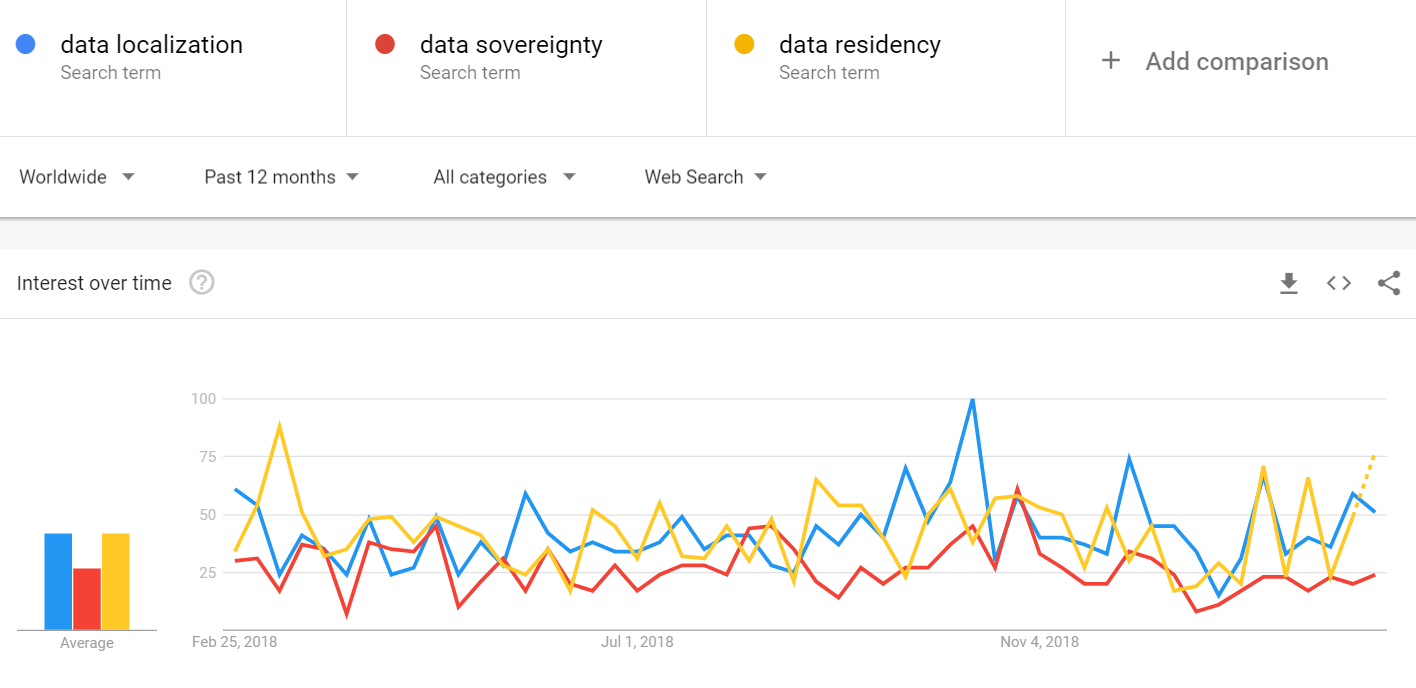
Data from Google Trends
Yet, why do these terms exist? And why are they used so interchangeably? What are their practical – not just philosophical – differences? And why do businesses need to keep on top of them?
How do the three terms interrelate?
They are effectively three degrees of a single concept: how data privacy impacts cross-border data flows. This subject has become increasingly important in recent years, with last year’s GDPR legislation granting greater rights to individuals over how their data is used by businesses both within and outside the European Union.
Research conducted by Insights for Professionals found that nearly 50% of IT leaders are concerned about data sovereignty/residency/control issues.
Organizations that handle international data must ensure that data privacy is not put at risk when shared across borders. Likewise, understanding the legal requirements of storing data in a certain country is fundamental to meeting data privacy and security standards.
1. What is data residency?
Data residency refers to where a business, industry body or government specifies that their data is stored in a geographical location of their choice, usually for regulatory or policy reasons.
A typical example of a data residency requirement in action is where a company wishes to take advantage of a better tax regime. Doing so will usually require the business to prove they are not conducting too great a proportion of core business activities outside that country’s borders – including the processing of data. They will therefore impose a data residency that requires them to use certain infrastructures, and then impose strict data management workflows on themselves and any cloud service providers in order to protect their taxation rights.
Don't let cloud security threats go unnoticed
Equip your team with the right tools to improve visibility, reduce risk & respond to threats faster.
VISIT THE HUB ifp.ClickDetails"2. What is data sovereignty?
Data sovereignty differs from data residency in that not only is the data stored in a designated location, but is also subject to the laws of the country in which it is physically stored. This difference is crucial, as data subjects (any person whose personal data is being collected, held or processed) will have different privacy and security protections according to where the data centers housing their data physically sit.
This difference is also crucial for businesses, as a government’s rights of access to data found within its borders differ widely from country to country. This is where data sovereignty and residency are often conflated. Ensuring data sits within a geographical location for whatever reason - whether avoiding or taking advantage of laws, regulations and tax regimes, or even for pure preference and comfort - is a matter of data residency. But the principle that the data is subject to the legal protections and punishments of that country is a matter of data sovereignty.
They are clearly related, and even two sides of the same coin, but one is a matter of national legal rights and obligations, while the other is a matter of geography. Recognizing this distinction will help professionals better prepare for compliant data management and exchange.
3. What is data localization?
This is the most stringent and restrictive concept of the three, and like data sovereignty, is a version of data residency predicated on legal obligations. It is also the concept that is growing the fastest internationally.
Data localization requires that data created within certain borders stay within them. In contrast to the two terms above, it is almost always applied to the creation and storage of personal data, with exceptions including some countries’ regulations over tax, accounting and gambling.
In many cases, data localization laws simply require that a copy of such data be held within the country’s borders, usually to guarantee that the relevant government can audit data on its own citizens (provided there is due cause) without having to contend with another government’s privacy laws. India’s draft Personal Data Protection Bill is an example of exactly this (you can see more discussion of the Bill in our Director of Data Privacy Services’ blog here).
However, there are countries where the law is so strict as to prevent it crossing the border at all. For instance, Russia’s On Personal Data Law (OPD-Law) requires the storage, update and retrieval of data on its citizens to be limited to data center resources within the Russian Federation.
Typical criticism of these laws is that they use the mask of enhanced cybersecurity or citizens’ privacy concerns to conceal the real motivation of national protectionism. This border-based siloing of data, it is claimed, obstructs businesses and governments from realizing the full potential that data stands to offer, and contributes to digital factionism and the “splinternet”.
But regardless of the debates surrounding the practices, we find that execs often need to better understand the importance of the differences between these three terms. As data privacy professionals, we may be sticklers for using the right vocabulary in the correct circumstances, but the frequency and manner in which these words are used interchangeably amongst the businesses we engage with, and even other industry commentators, indicates a dangerously widespread misunderstanding.
Addressing any level of confusion in your own business will allow you to identify the precise obligations that apply to you and interrogate your cloud service providers’ capabilities more rigorously.
As a starting point, try applying the above distinctions to these key questions about your own infrastructure:
- Where are each of your various categories of data (personal data, financial records, etc) created or processed and what obligations might this bring?
- Where is it then stored, and who owns the data center? Your data may be in a data center in the UK, but if this data center is owned by a US-headquartered company, then the US Government may have the rights to access your data under the CLOUD Act.
- What are your procedures for back-up? Where is your data backed up to? According to the type of data in question, what local stipulations exist for the security or encryption of that data?
- How confident are you in your cloud partner(s) understanding of current and future data privacy regulations? How have they evidenced that their data centers meet all your local and global privacy needs, or have you assumed it?
Further reading:
- Everything You Need to Know About Cloud Security
- The 11 Most Important Questions to Ask Any Cloud Vendor
- 3 Cloud Data Compliance Problems You Didn't Know You Had
- 5 Steps to Build a Successful Cloud Center of Excellence
Access the latest business knowledge in IT
Get Access




Julian Box
Julian Box is the founder and CEO of Calligo, the data optimization and privacy specialists. Calligo offers a portfolio of data services that optimize every stage of the data journey and that are uniquely designed to be “privacy-first”.
Comments
Join the conversation...