

Having a server go down is a nightmare scenario for any business. An unexpected crash can leave your business completely unable to operate and could, in severe circumstances, see vital data irretrievably lost. Or, in less serious instances, your website could just go offline for a few minutes while you turn it off and on again.
But how do you know which of these scenarios you're facing? The first step in fixing an unexpected server crash is understanding exactly what the root cause of the problem is. Only then will you be able to put in place backup procedures and mitigation processes to get the server up and running again and run contingencies to ensure you can continue operating in the meantime.
However, with so many potential things that can go wrong, this may not always be an easy task. Therefore, here's a quick primer for some of the key questions you should be asking, as well as some of the most common root causes of a crash that you need to be aware of.
Step one: What type of crash is it?
The first thing you need to do is establish what type of crash you're faced with. This will help you narrow down the root cause - for example, if it is a hardware or software issue - and serve as a good starting point for your diagnostics.
For instance, does the server power on at all? If not, then it's definitely a hardware issue, most likely related to the power supply. If it boots up but this shows the dreaded Blue Screen of Death (BSoD), this is usually an indicator of a hardware failure or a bad device driver.
Meanwhile, if the server loads, but critical services aren't functioning, this can suggest a network problem or configuration issue. These can be among the hardest issues to pin down, as there could be a wide variety of potential causes, so it's important to know where to look for further clues.
Also, don't forget the simple stuff! It can be easy to focus so closely on more complex, technical issues deep within the configuration of a server that more basic issues can go completely overlooked. There are many tales in the industry of admins going through lengthy troubleshooting processes, only to find someone has simply unplugged the wrong cable and shut down the server.
Step two: Deciphering the errors
If you're staring at a BSoD, it can feel daunting having a long string of errors to look at. However, if you understand the structure of the screen, it becomes a lot easier to make sense of it. In particular, one key area to focus on is the actual error message that appears at the top of the screen.
Here are some of the more common messages you may encounter here, as well as what they indicate:
- KMODE_EXCEPTION_NOT_HANDLED. This indicates an incorrectly configured device driver.
- REGISTRY_ERROR. There is a serious problem in the registry.
- INACCESSIBLE_BOOT_DEVICE. The operating system is unable to read from the hard disk.
- UNEXPECTED_KERNEL_MODE_TRAP. Signifies memory problems.
- BAD_POOL_HEADER. This can be hard to interpret, but indicates that the issue has something to do with a recent change in the system.
- KERNEL_DATA_INPAGE_ERROR. The OS is unable to read a page of kernel data from the page file.
- NMI_HARDWARE_FAILURE. This indicates the inability of the hardware’s abstraction layer to identify the cause of the error.
- NTFS_FILE_SYSTEM. You have a corrupted hard disk.
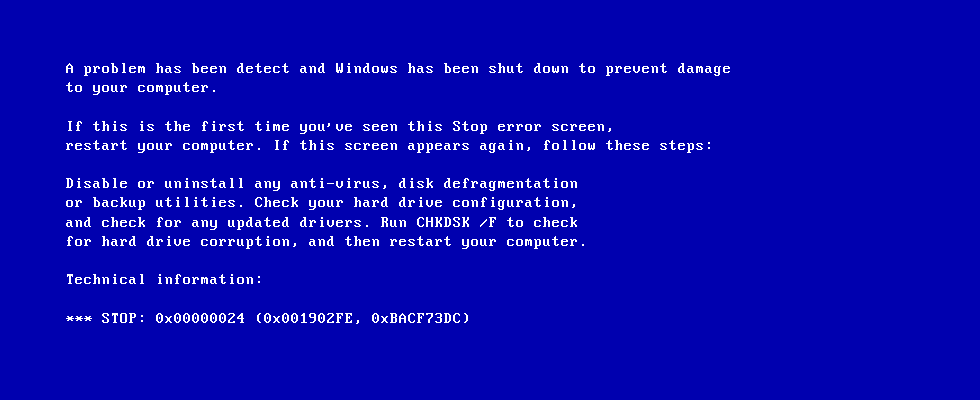
Below the error message, you'll see a list of OS modules that have been loaded into the memory successfully, so you can rule these out as the cause. Then, there is a list of those that didn't load, which could help you narrow down the issue to a specific module.
Step three: Using Safe Mode and event logs
The next thing to try is booting up your server in Safe Mode. If you can't do this, then the chances are your issue is hardware-related. If you can, this points to a driver-related issue.
If you're able to boot into Safe Mode, this will give you access to the Event Viewer, which should be able to offer further clues as to what the cause of the problem is. But if not, you can then turn to Device Manager and disable all devices that are not required for the server to start.
Turn them on one by one and reboot the server to see which, if any of them, are causing the problem by process of elimination. When you enable a device and the server crashes again, there's your issue.
Once you've narrowed it down, the hard work begins. Depending on the type of problem you've encountered, a fix could be as simple as rolling back a new change or updating a configuration. Or, more complicated problems will need expert attention and could take much longer to resolve, in which case, you'll need to have backups and contingencies at the ready to ensure continued service.
How to spot a server crash before it happens
Of course, the easiest way to get through an unexpected server crash is to prevent it before it occurs. Doing so can be tricky, and predicting the future is never going to be 100% certain, but there are a few tell-tale signs of server issues that you can use to fix problems before they lead to a full-on crash. Here are some of the best crash prevention methods:
1. Check your server temperature
This might sound simple, but temperature is one of the biggest factors when it comes to server reliability. One long-term test found that the best temperature at which to keep servers is between 59 and 68°F, and high temperatures in particular are a clear sign that something is wrong.
This could be an external issue; if your server room has inadequate ventilation, it will naturally heat up and cause problems with your hardware. However, it could be the other way around. If a server is running hot despite the temperature of the room, that’s a sign there’s something wrong and it should be examined before it crashes.
2. Run a few stress tests
One common cause of server crashes is simply high levels of traffic. To spot problems before they occur, it’s important you get a good idea of how much traffic your server can cope with; that way, you can use network monitoring software to see in real-time if your systems are being pushed to the brink.
Stress testing can be done in a number of ways, but one of the most common is to create a number of virtual users and see if the server can handle them. If it can, increase the number of users. If not, decrease them. Eventually, you’ll come across your server’s approximate crash point, and use that figure to spot future failures before they occur.
3. Check your warranty and timeline
Manufacturers will provide you with a warranty, and this will give you a good idea of how long your servers will last without issue. They’ll also provide you with a recommended replacement timeline, and this shouldn’t be ignored.
Usually, this will be between three and five years, but it’s extremely rare to find any timeline longer than five years. After this point, it’s thought that servers become around twice as expensive to support. This is partly due to the likelihood they’ll crash, so if your servers are approaching the end of their lifespan this is a clear red flag.
4. Are data transfers slowing down?
A crash doesn’t have to mean a catastrophic failure; often, they come in the form of a major slowdown across your systems. The benefit of this is that if you have a good handle on how fast data is usually transferred, you’ll be able to spot these slowdowns when they first start and be better able to prevent a full server crash.
Your transfer speed will depend on your hardware and whether you’re using Wi-Fi or Ethernet. Bear in mind that it’s very unlikely you’ll run at peak speed; for example, if your network can handle transfer speeds of 1,300 Megabits per second (Mbps), you should expect around 1,000 Mbps on an average day.
Access the latest business knowledge in IT
Get Access

Tech Insights for Professionals
Insights for Professionals provide free access to the latest thought leadership from global brands. We deliver subscriber value by creating and gathering specialist content for senior professionals.



Comments
Join the conversation...